ich habe seit ein paar Wochen das Problem das einige Aktionen zeitweise nur sehr zeitverzögert ausgeführt werden. Beispielsweise klingelt es (Wago )erst 10 Minuten nach Druck auf den Klingelknopf (FS20). Dann ist der Besucher aber schon wieder weg.
Ich vermute das die logging.db daran schuld ist. Diese zeigt seit ein paar Wochen ein sehr starkes Wachstum. Mittlerweile ist sie bereits 54GB (GIGABYTE) groß und wächst jeden Tag um mehrere Hundert Megabyte.
Wie kann ich das stoppen? Da muß doch irgendwo was faul sein.
Vor ein paar Wochen ist das System abgestürzt da der Hyper-V Host voll war. Vielleicht ist da irgendwas passiert. Aber nun ist die virtuelle IPS-Maschine (Win 7, Hyper-V 2012 Gast) kurz vor dem Bersten. ist hab noch knapp 4 GB Platz.
Ich habe nun eine geloggte Variable entfernt (Heat_Index der Wetterstation). Angestoßen habe ich das ganze um 11:17. Die logging.db ist nun stabil (keine Änderung seit 11:17), dafür ist die logging.db-journal in 30 MInuten auf 900 MB angewachsen.
Hängt das mit dem löschen zusammen?
Das db-journal ist so etwas wie ein temp-Speicher für reinlaufende Logging-Daten und wird normalerweise (zwingend) alle 60 Sekunden in die DB überführt.
Das scheint bei Dir nicht zu klappen, ich tippe auf eine defekte DB.
Nach 1,5 Stunden ist IPS nun fertig mit dem entfernen der einen geloggten Variable. Jetzt hat er auch das Journal zurückgeschrieben. Die Datenbank war wohl während der Zeit gelocked.
Er schreibt jetzt wieder artig alle 60 Sekunden zurück.
Was mich ein wenig irritiert ist die Datenmenge die da in einer Minute anfällt. Das Journal ist nach einer Minute ca. 30-35 MB groß.
deinen Analyzer habe ich mir gestern Abend bereits downgeloaded und installiert. Dabai habe ich aber wahrscheinlich einen Fehler gemacht:
Ich hatte die Original-DB umbenannt. IPS hat dann eine neue erstellt. Ich habe dann deinen Analyzer installiert und gestartet. Es waren auch Werte drin. Dann habe ich IPS beendet und die originale (also die 50GB Datei) Datenbank wieder eingebunden. Jetzt zeigt mir der Analyzer nur noch die Daten vom Test, also nur ein paar Daten.
Kann ich den Analyzer wieder zurücksetzen oder sollte ich ihn komplett löschen und neu installieren?
Der RS DB Analyzer läuft einmal pro Tag (kurz nach Mitternacht) und macht so etwas wie einen Snapshot von den Daten in der DB.
Wenn Du morgen reinschaust, hast Du die Werte, die zu Deiner aktuellen DB passen.
Wenn Du die Historie (mit den daten aus der Test-DB) nicht haben willst, löchst Du am am besten alle .csv-Files im Ordner ‚…RSDB_Analyzer\csv‘. Durch manuelles Starten des Config-Scripts bekommst du dann den Installations-Zustand.
Ich geb mal einen kleinen Zwischenstatus:
Schweren Herzens habe ich letzte Woche die Datenbank umbenannt und so IPS zum Erstellen einer neuen Datenbank gezwungen. Nach einer Woche Logging (ohne große Änderung am Log-Verhalten) hat die neue Datenbank eine Größe von weniger als 9 MB.
Ich habe dann direkt nach dem umbenennen die defekte DB auf ein anderes Blech gezogen und den Wiederherstellungsbefehl der in der IPS Doku steht ausgeführt.
sqlite3.exe logging.db.backup .dump | sqlite3.exe logging.db
…Es läuft immer noch, mittlerweile seit 7 Tagen.
Wenn das durch ist versuch ich mal eine Datenverdichtung.
Wenns denn klappt.
Dann fehlt mir zwar hinterher 2-3 Wochen aber besser als jetzt, 4 Jahre fehlen mir zur Zeit.
BTW Gestern hat der Stromnetzbetreiber RWE (Abteilung RWE Metering)bei mir einen Smarten Stromzähler montiert, ich bin einer von 653 Testkunden. Zum Dank wurde mir ein RWE Smarthome Starterset überreicht, damit ich bei mir eine Hausautomation aufbauen kann
Wenn wir doch alle auf dem Weg weg von der Datenbank sind und hin zur csv Lösung, dann überführt doch die Altdaten in csv und fertig. Dann hat man doch alles gesichert und verfügbar.
Du bist der DB-Spezi. Ich hatte nur was im Hinterkopf, dass die csv’s die Rohdaten enthalten und Aggregation später irgendwie live stattfindet. Kann mich auch irren.
Die Ideee ist gurndsätzlich ziemlich gut, nur aktuell für den operativen Betrieb (WIN-OS) nicht realisierbar. Was aber sicher nicht schaden kann ist:
beide Datenbanken aufbewahren und die fehlenden Zeiträume als CSV zusammenführen, wenn eine betriebsfähige csv-Lösung da ist.
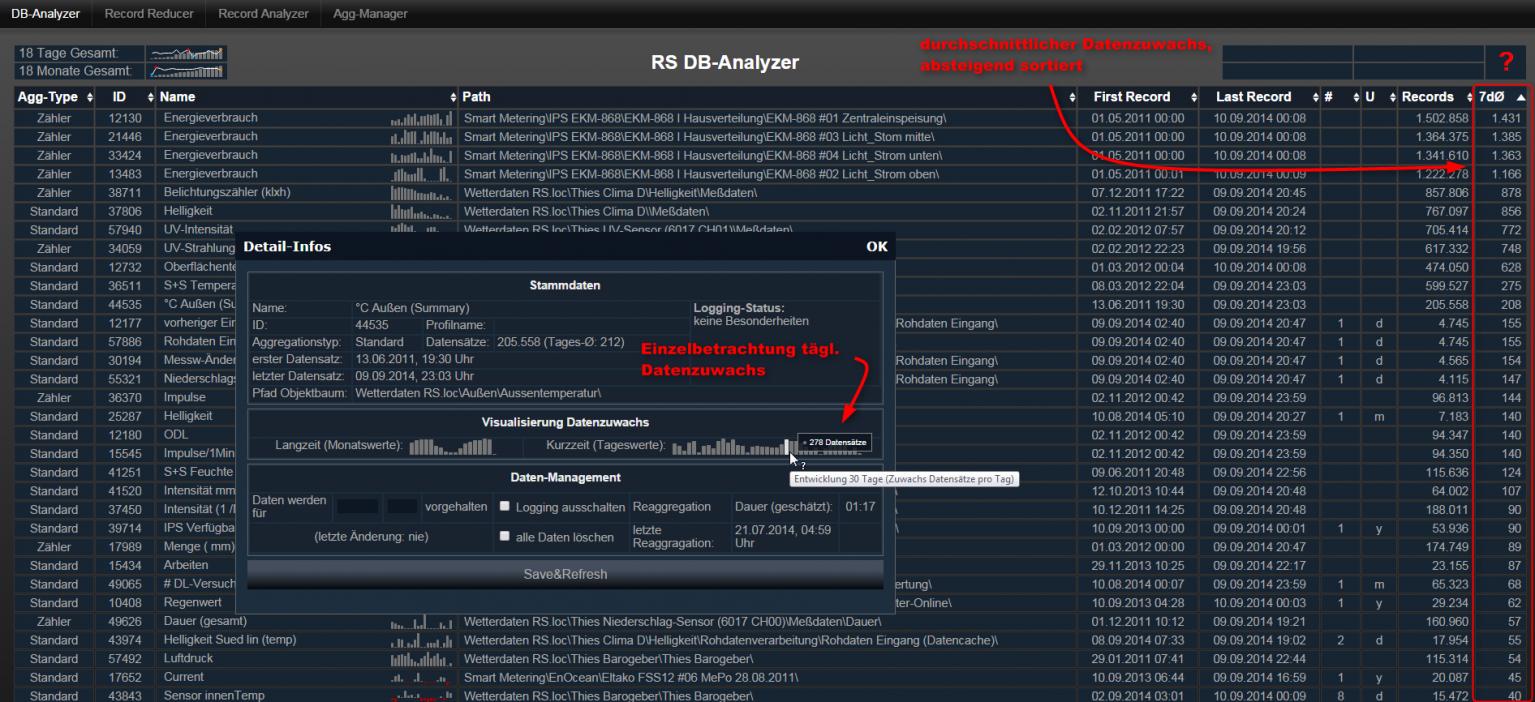
 . Geh mal in den Archiv-Handler und prüfe nach welche Variablen da massiv Datensätze aufweisen.
. Geh mal in den Archiv-Handler und prüfe nach welche Variablen da massiv Datensätze aufweisen.