Hallo,
ich habe folgende Situation:
ich habe ein Script, in dem nach bestimmten Kriterien zu bestimmten Zeiten HM-Gerät geschaltet werden.
Mache ich natürlich ganz normal mit HM_WriteValueBoolean() (e.a.).
Den Rückgabewert der HM_WriteValue*()-Funktionen werte ich aus und bekomme so mit, ob es funktioniert hat oder auch nicht.
Es ist also nicht jede Aktion ein Script das über ein Zeit-Ereignis ausgelöst wird sondern es ist ein Script, das eventuell mehrere Schaltvorgänge, die „zum gleichen Zeitpunkt“ stattfinden sollen, nach einander auslöst. Also eigentlich prima serialisierte HM_WriteValue-Aufrufe, das sollte eigentlich nix schief gehen.
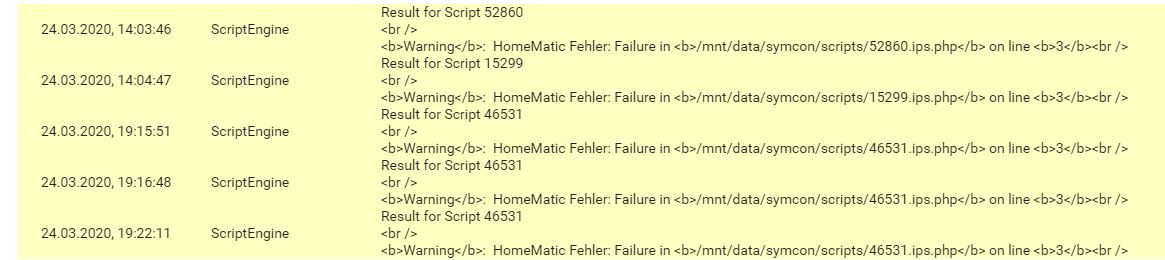
Das funktioniert wunderbar … solange alle Aktoren einwandfrei angesprochen werden können.
Meine Beobachtung ist diese: ist eine Komponente nicht erreichbar, wird von HM_WriteValue*() nach relativ genau 5 Sekunden ein false zurückgeliefert. Alle - in einem gewissen Zeitraum - danach erfolgenden Schaltvorgänge schlagen ebenfalls fehl, auch wenn dieser Autor einwandfrei erreichbar ist. Die Schaltbefehle werden sogar zum Teil ausgeführt, nur IPS meint, das wäre schief gegangen.
Die HM-IO-Instanz ist i.d.R. in diesen Situation unverändert verbunden, zeigt also typischerweise kein Operation aborted an.
Auch wenn es selten vorkommt … mich nervt das etwas, und daher würde ich gerne etwas daran ändern, das einzelne fehlgeschlagenen Operationen für einige Zeit alle Aktionen blockieren.
Da ich eine Schalt-Aktion nach der anderen mache, dachte ich, das sollte ja kein Problem sein - ist aber definitiv und nachvollziehbar ein Problem,
Dann habe ich gedacht, warte nach einem Fehler mal ein paar Senkungen … ein paar Sekunden helfen aber nicht.
Dann habe ich die Zeit auf 30 Sekunden ausgedehnt - reicht mal, mal auch nicht.
Da das Ganze in einem Script läuft bin ich natürlich daran gebunden, das ich insgesamt nur 30s zur Verfügung habe. Ich würde aber altennativ diese Schaltvorgänge auch über eine Queue laufen lassen und das dann verzögert abarbeiten.
Das macht aber nur dann wirklich Sinn, wenn ich entweder testen könnte, ob die CCU nach einem vorigen Abbruch wieder bereit ist oder eine Zeit finde, die mit hoher Wahrscheinlichkeit reicht. Einfach nach einem Fehlschlag x Minuten zu warten bis zur nächsten Operation ist vielleicht etwas zu simpel.
Hat da jemand ein Hinweis für mich, in welche Richtung ich denken oder wo ich meine Suche intensivieren sollte?
Rein interessehalber: sind die 5 Sekunden, bis eine Operations als fehlgeschlagen gemeldet wird, eigentlich irgendwo einstellbar? In der IO-Instanz nicht, da gibt es nur 30-Sekunden-Intervalle und auf der CCU-Seite kenn ich da auch keine Einstellung.
demel



")