Hallo zusammen,
ich habe in den letzten anderthalb Jahren ein eigenes Sprachsteuerungssystem für Smarthomes entwickelt. Da das ganze Projekt nun einen Reifegrad erreicht hat, dass es über eine simple Spielerei hinausgeht und da ich für meine Hausautomation auch IP-Symcon verwende und daher hierfür auch ein Plug-In entwickelt habe, möchte ich – entsprechendes Interesse vorausgesetzt – das ganze gerne mit der Community teilen.
Derzeit kann ich noch nicht versprechen in welchem Umfang ich das ganze teilen werde, da ich aktuell auch mit dem Gedanken spiele das ganze Projekt zu kommerzialisieren (interessierte Integratoren sind herzlich willkommen). Aktuell suche ich (fähige) Betatester und würde gerne mehr darüber erfahren, was die IPS-Community von meinem Ansatz hält. Später werde ich das Projekt vermutlich für die private Nutzung veröffentlichen.
Beweggründe für ein eigenes System und Angrenzung zu Alexa & Co
Wenn ich an Sprachsteuerung für Smarthomes denke, dann denke ich an eine Lösung wie den Board-Computer bei Star Trek TNG. Ein in sämtlichen Räumen verfügbares System, dass von seiner Struktur her auf die Smarthome-Anforderungen ausgelegt ist und so eine flüssige und kontextsensitive Interaktion ermöglicht. Wenn ich z.B. im Wohnzimmer bin und das Licht einschalten möchte, dann muss als Kommando „Computer, Licht!“ reichen. Denn das System sollte wissen wo ich mich befinden und dass das Licht aktuell aus ist und es somit eingeschaltet werden soll. Eine solche „natürliche“ bzw. kontextsensitive Integration ist schwierig mit den etablierten Systemen zu machen, da diese mit Ihrem riesigen Überbau an Skills etc. häufig ein relativ umständliches „Navigieren“ durch die Skills bedürfen. Hinzu kommen massive Sicherheitsbedenken, denn wer möchte schon wirklich in jedem Raum ein mit dem Internet verbundenes Mikrofon haben, das von einem internationalen Datenkraken-Konzern betrieben wird?!
Aufbau des Systems
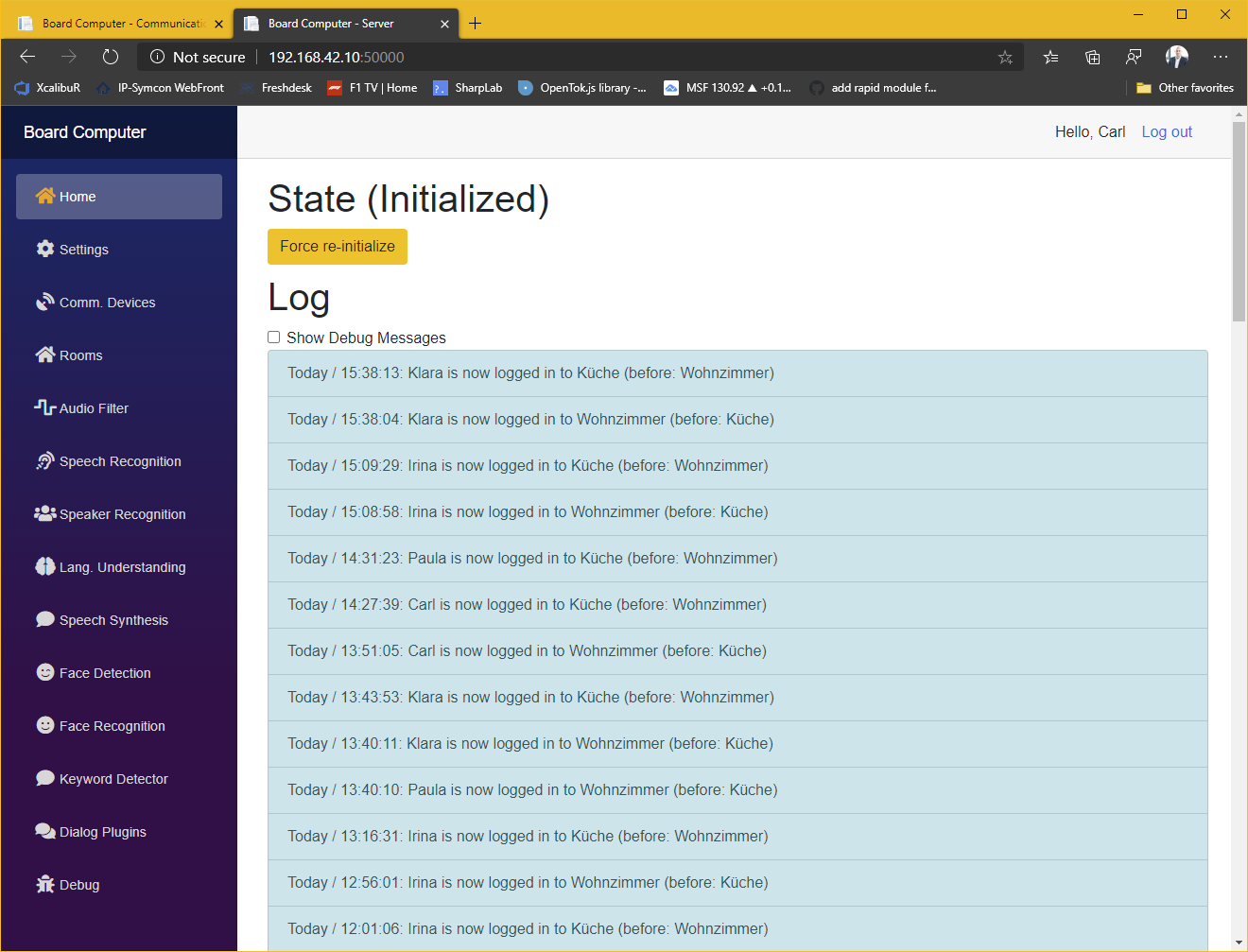
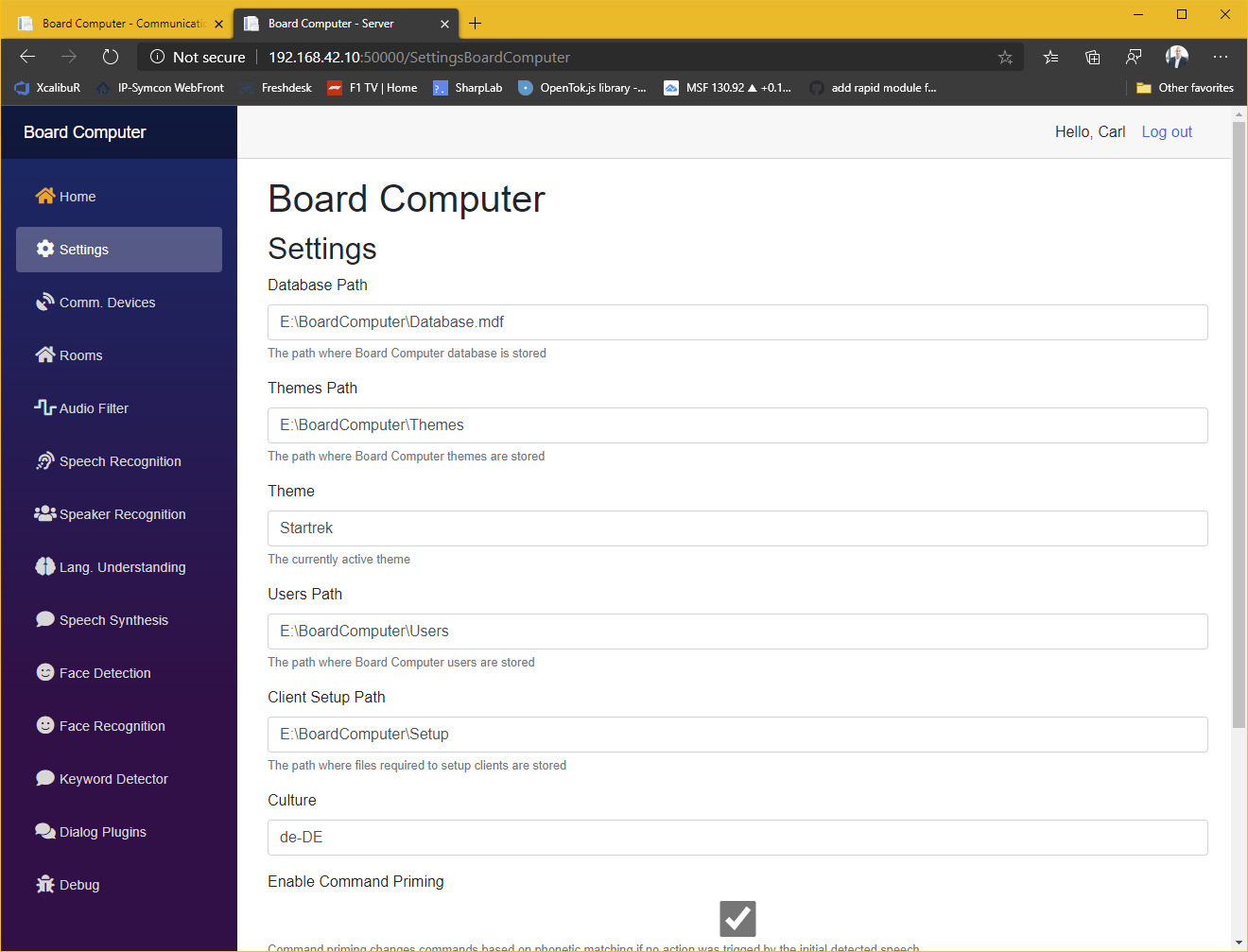
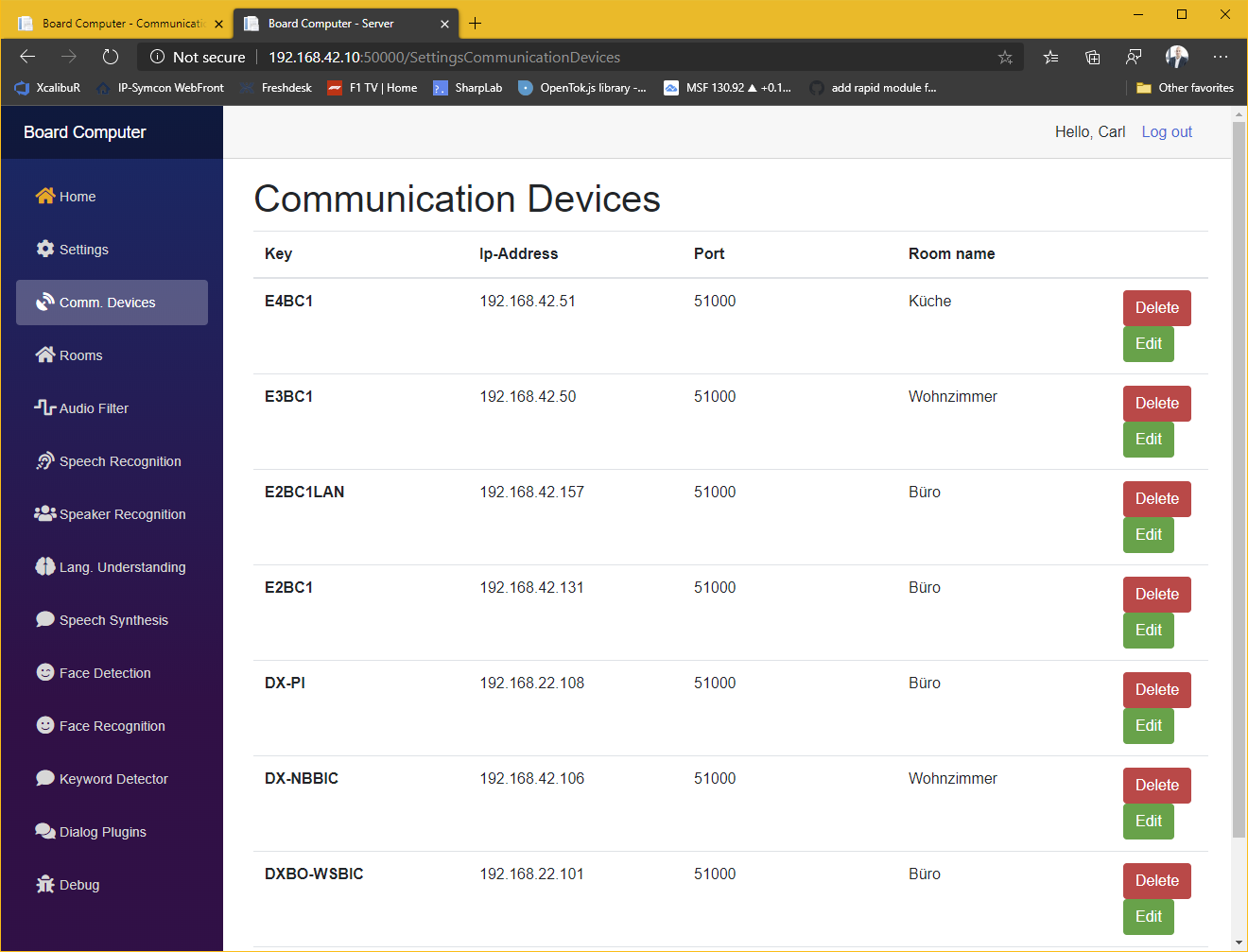
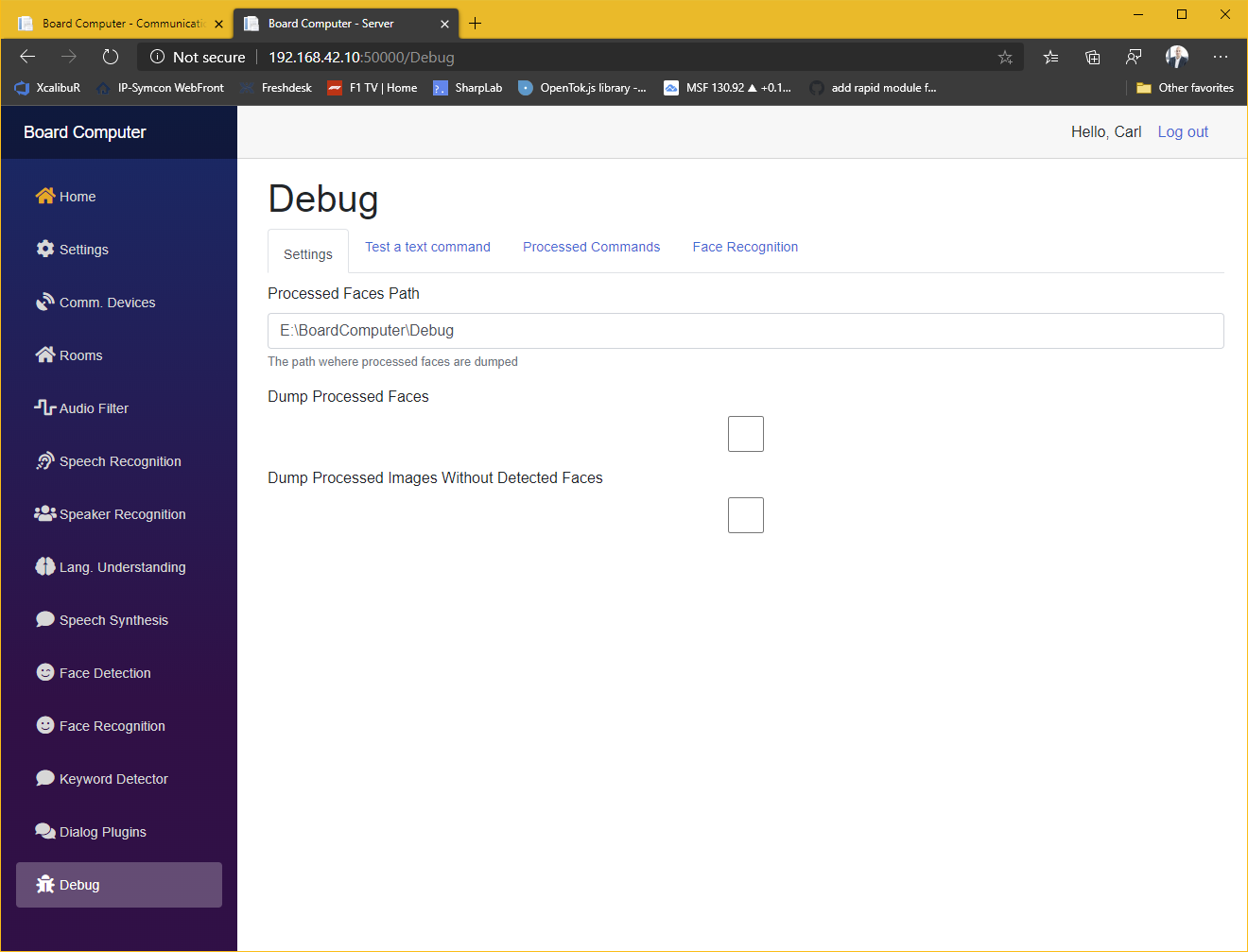
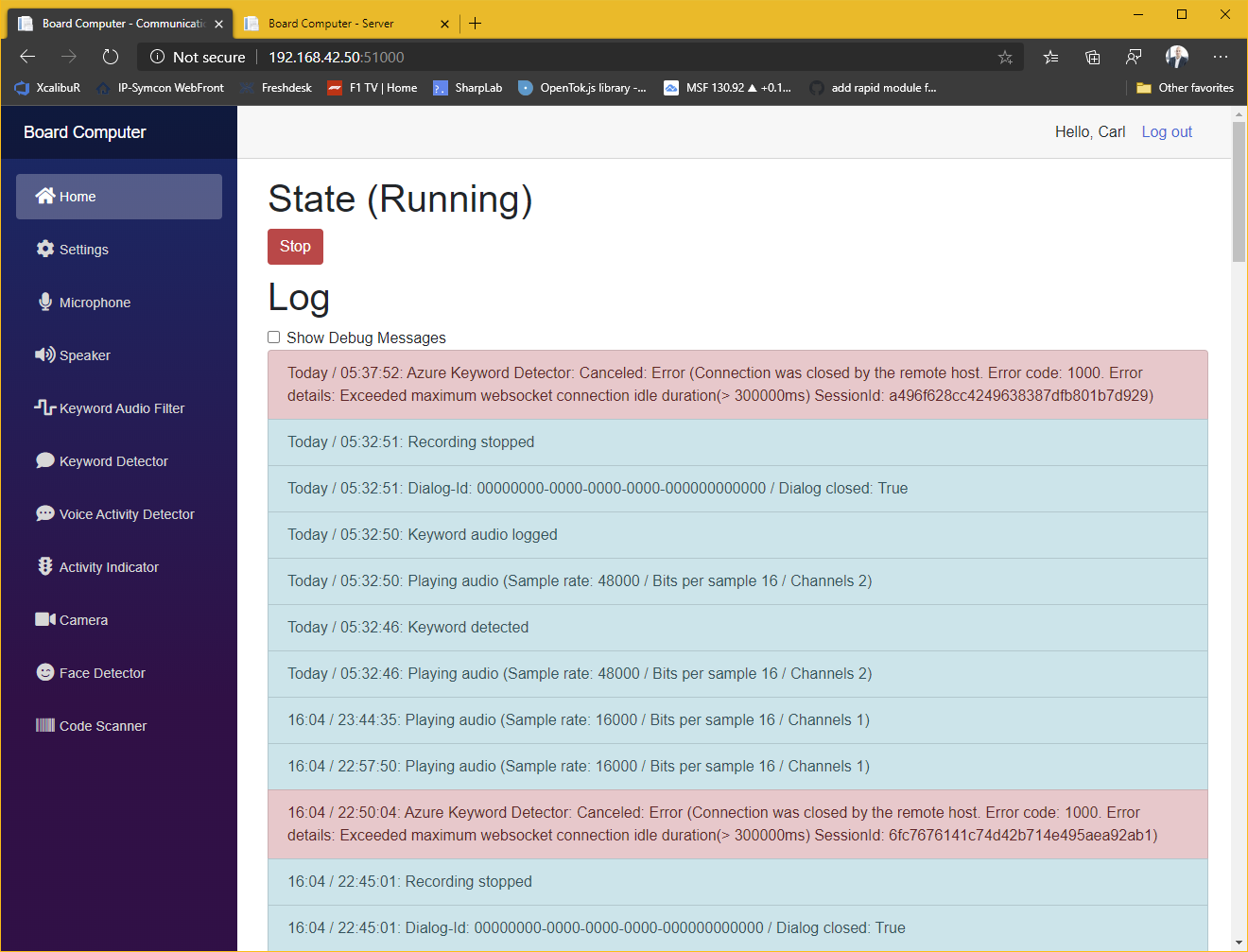
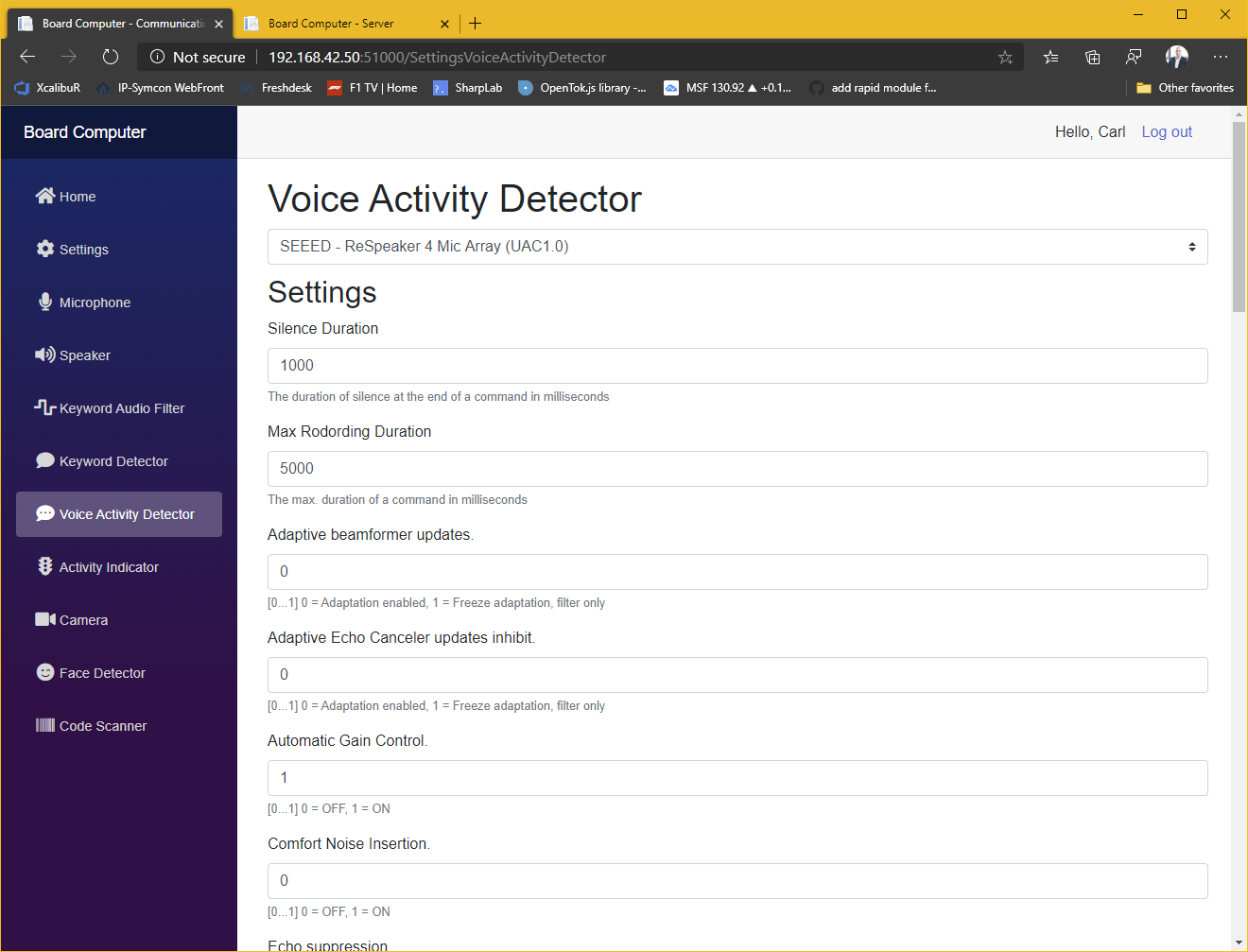
Das System besteht aus einer Serveranwendung und einem Client in jedem Raum. Derzeit bestehen die Raumeinheiten aus einem Mikrofon-Array, einem Raspberry Pi, zwei Lautsprechern, einen Netzteil und optional einer 360°-Kamera. Alles verpackt ein einem 3D-gedrucktem Gehäuse das bei mir unter der Decke in einer 3-Phasen-Stromschiene, mittig im Raum sitzt. Sämtliche Softwarekomponenten sind als Plug-In realisiert um eine auf unterschiedliche Bedürfnisse und Hardwareanforderungen optimierte Lösung zusammenzustellen. So ist z.B. eine komplett offline betriebene Lösung möglich oder eben auch eine die z.B. für „Sprache zu Text“ eine online-API verwendet, da diese häufig leistungsfähiger sind.
Funktionsumfang
Beliebiges Keyword
Je nach verwendetem Keyword-Detector-Plugin kann das Keyword frei vergeben werden. Ich verwende derzeit z.B. „Hey Computer“.
Sprechererkennung
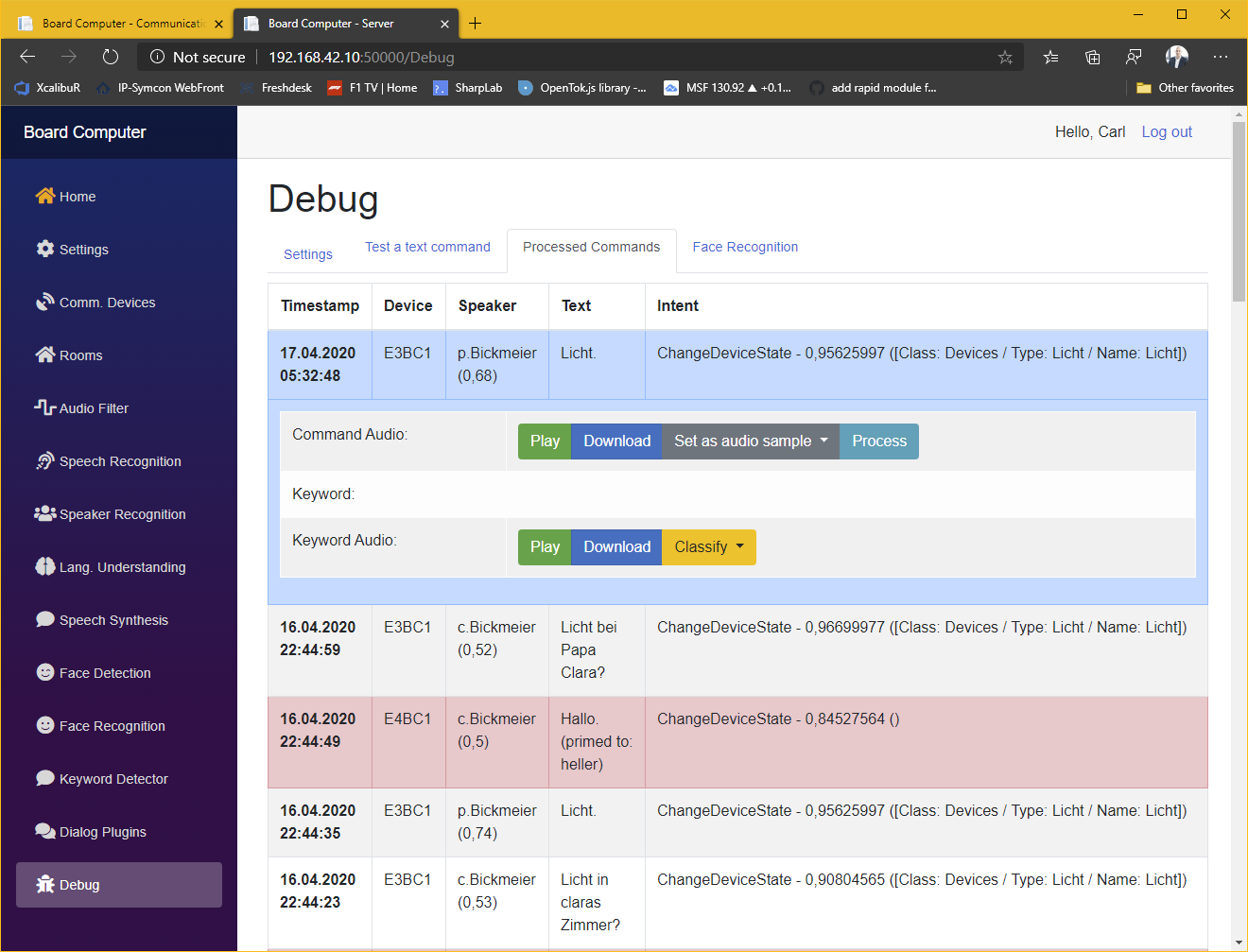
Das System erkennt bei jedem Kommando welcher User das Kommando gesprochen hat. Dies ermöglicht es ein und dasselbe Kommando bei unterschiedlichen Benutzern unterschiedlich zu interpretieren (z.B. das abspielen von persönlichen Playlisten etc.) oder bestimmte Kommandos auf bestimmte User zu beschränken.
Kontextsensitive Dialoge
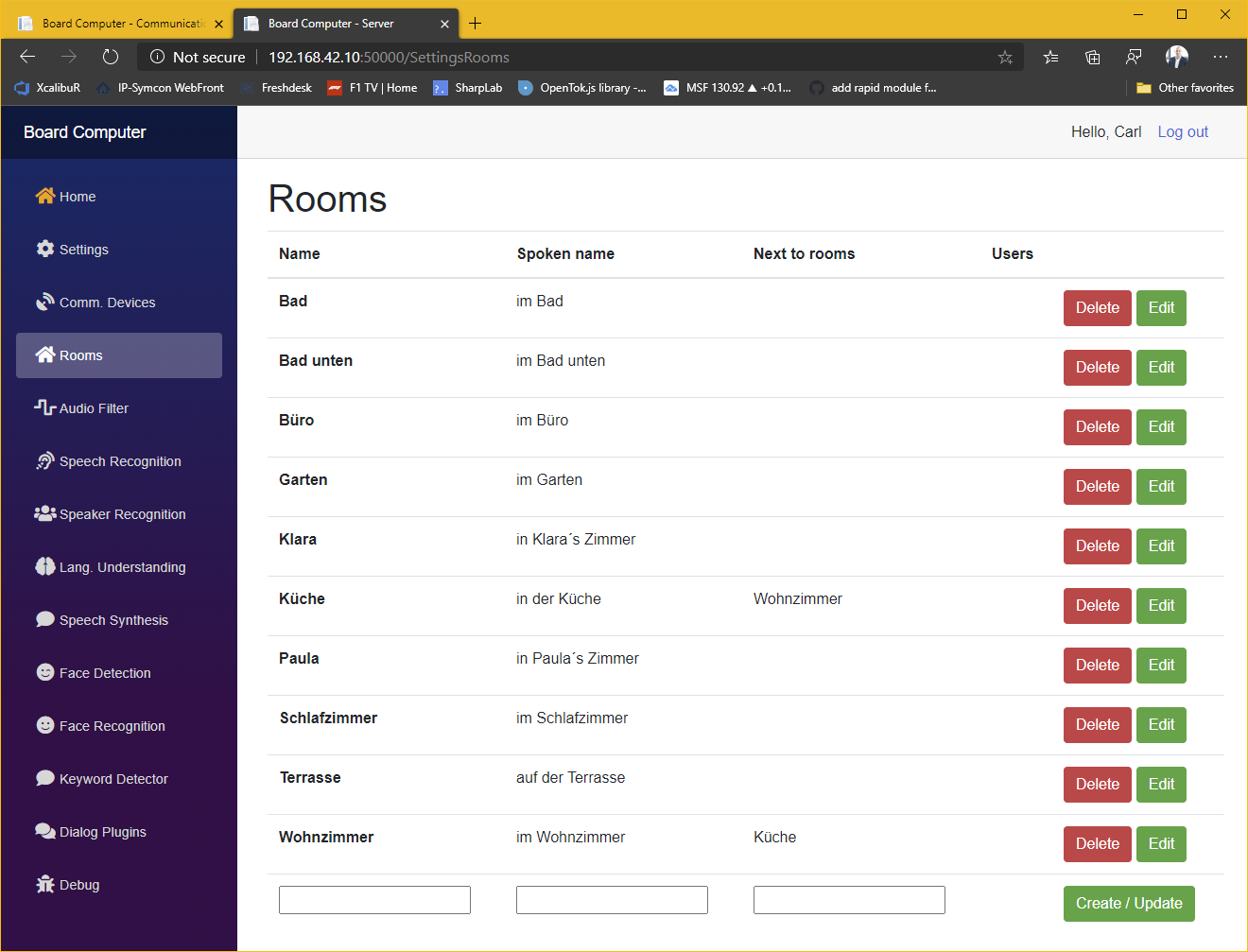
Wenn bei einem Kommando der jeweilige Raum nicht erwähnt wird, dann wird automatisch der Raum angenommen in dem sich die Raumeinheit befindet. So schaltet z.B. „Computer, Licht!“ immer das Licht im jeweiligen Raum ein bzw. aus. Man kann aber auch jederzeit sämtliche Teile eines Kommandos explizit erwähnen. So schaltet z.B. „Computer, Licht in der Küche aus!“ immer das Licht in der Küche aus, egal in welchem Raum das Kommando gesprochen wurde.
Multiroom-Kompensation
In der Konfiguration der Räume kann angegeben werden, welche Räume sich nah beieinander befinden. Denn in machen Konstellation lässt es sich nicht verhindern, dass mehrere Raumeinheiten auf ein Kommando reagieren. In diesem Fall verwirft das System alle aus nah beieinander liegenden Räumen eingehende Kommandos und führt nur das im Durchschnitt lauteste aus.
Command Priming
Kommandos die aufgrund von Nebengeräuschen etc. mal nicht korrekt erkannt werden, können basieren auch einem phonetischen Abgleich abgeändert werden um die Erkennungsrate zu verbessern. So wird z.B. aus „Rollanden aus“ „Rolladen auf“ etc.
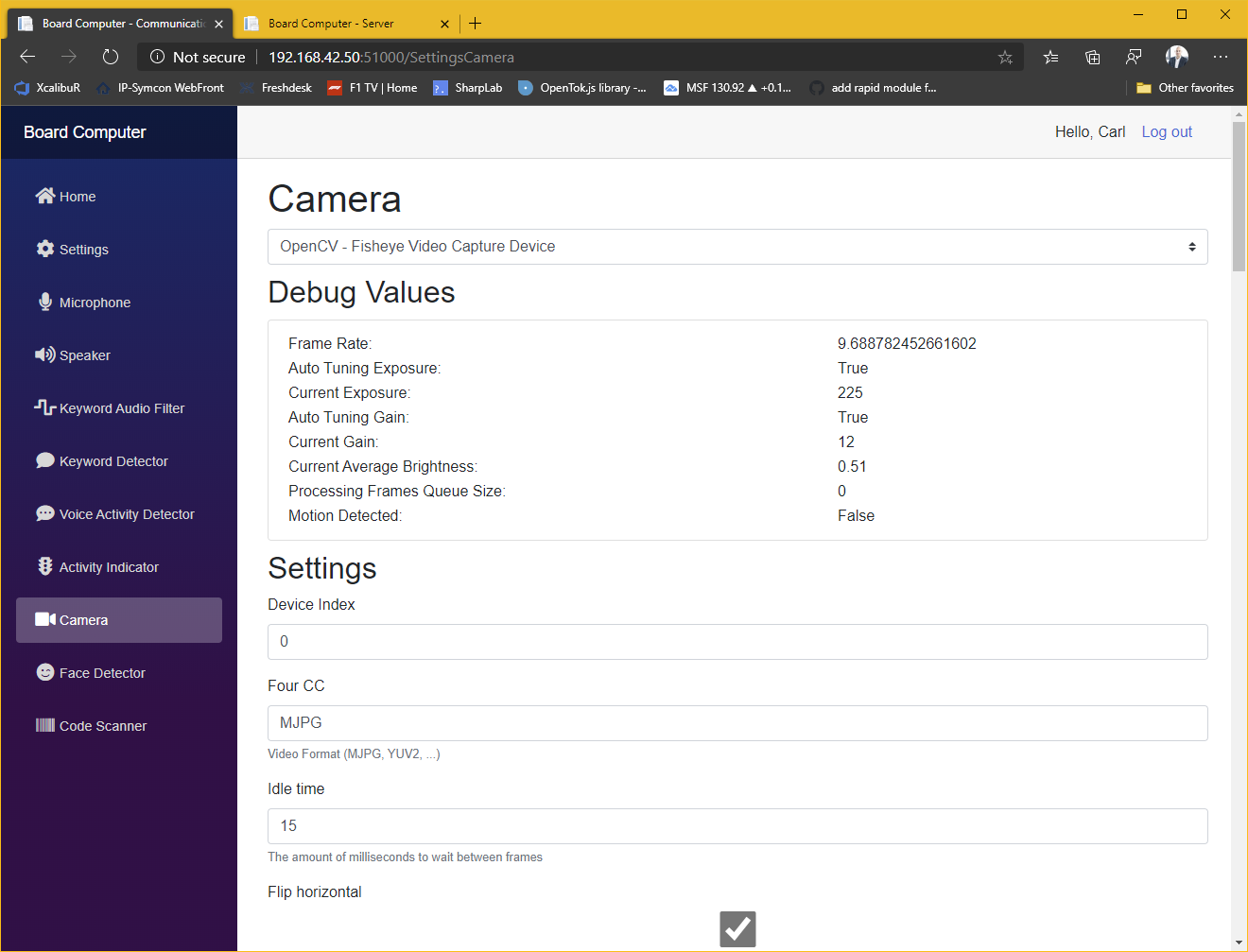
Präsenzerkennung mittels Gesichtserkennung
Wenn in einer Raumeinheit eine Kamera verbaut ist (360°-Fishaugenkameras werden unterstützt), dann kann das System mittels AI-basierter Gesichtserkennung ermitteln welcher User sich in welchem Raum aufhält. Dies ermöglich z.B. in der Küche einen Timer zu erzeugen und die Erinnerung kommt dann z.B. aus der Raumeinheit im Büro weil man sich hier aktuell aufhält. Später wird es auch möglich sein das System als Gegensprechanlage zu nutzen. Zum herstellen einer Verbindung reicht es dann aus, den User zu nennen mit dem man sprechen möchte, unabhängig davon in welchem Raum sich dieser aufhält. Ein weiteres Anwendungsbeispiel wäre die automatische Anpassung an die Präferenzen eines Users, wenn dieser einen Raum Betritt.
Scannen von Barcodes
Wenn in einer Raumeinheit eine Kamera verbaut ist, können über diese Bar- / QR-Codes gescannt werden um Dialoge zu initiieren (z.B. um ein Produkt auf eine Einkaufsliste zu setzen oder im Internet den günstigsten Preis für ein Produkt zu suchen etc.)
AI-gestützte Geräuschunterdrückung
Sowohl in den Raumeinheiten für eine bessere Erkennung des Keywords bei Umgebungsgeräuschen wie z.B. Musik, laufender Fernseher etc. als auch im Server für die Verbesserung der Spracherkennung, kann ein Noisecanceling-Plugin aktiviert werden. Derzeit verwende ich hier z.B. RnNoise, dass mittels eines neuralen Netzes nahezu alle Umgebungsgeräusche bis auf die menschliche Sprache filtert.
Ausgabe von Sprachnachrichten
Über eine simple Rest-API können Sprachnachrichten an Räume und / oder User gesendet werden. So ist es z.B. möglich aus einem IPS-Script heraus eine Sprachnachricht auszugeben, wenn ein Bewegungsmelder ausgelöst wird etc. (perfekt wenn man wissen möchte ob die Kids wirklich schlafen  )
)
Dialog-Plugins
Dialog-Plugins ermöglichen es dem System mit anderen Systemen zu interagieren. Derzeit habe ich mich natürlich auf die Systeme konzentriert, die ich selber nutze. Das Plug-In-Modell erlaubt es aber den Funktionsumfang sehr einfach zu erweitern. Hier eine „grobe“ Beschreibung des aktuellen Funktionsumfangs.
Ip-Symcon
- Ermöglicht das steuern von diversen Geräten (Homematic, Hue, Denon, Shuttern etc.). Sicherlich nicht alles was ihr so braucht, aber das lässt sich easy erweitern.
- Ausführen von Skripten
- Rückmeldung des Kommunikationsstatus in den einzelnen Räumen (ermöglicht z.B. das herunterregeln des Verstärkers, während ein Kommando abgesetzt wird etc.)
- Rückmeldung des Aufenthaltsortes von Personen (ermöglicht z.B. die Anpassung eines Raumes an den am höchsten Priorisierten Nutzer etc.)
- Abrufen von Geräte-Stati („Computer, Status Fenster im Schlafzimmer“ etc.)
Waboxapp
- Ermöglicht das Versenden von Whatsapp-Nachrichten
Microsoft Exchange
- Ermöglicht den Zugriff auf Exchange-Kalender („Computer, was habe ich übermorgen vor?“ usw.)
Microsoft Xbox Smartglas
- Ein- und ausschalten von X-Boxen
- „Nächster Titel“, „Pause“, „Abspielen“ etc. z.B. bei Netflix oder Youtube usw.
Microsoft Graph
- Hinzufügen von Einträgen auf Microsoft To-Do-Listen (ehemals Wunderlist)
- Hinzufügen von Notizen zu OneNote
Date & Time
- Abfragen der aktuellen Uhrzeit etc.
Sonos
- Starten und stoppen von Sonos-Boxen
- Laden von Sprecherabhängigen Playlisten
Funktions-Plugins
Neben die Dialog-Plugins, die es dem System ermöglichen mit externen Systemen zu interagieren, gibt es auch noch eine Vielzahl an „Funktions-Plugins“ die die einzelnen Teilschritte ermöglichen (z.B. Ansteuern von Mikro und Lautsprecher, Noisecanceling, Sprache zu Text, Text zu Sprache, Gesichtserkennung, Sprechererkennung etc.). Diese Plugins ermöglichen es dann auch Systeme nach den eigenen Anforderungen (Funktion, Hardware, Sicherheit, Lizenzkosten etc.) zusammenzustellen. Die Beschreibung dieser Plugins ist mir aktuell zu aufwendig, bei entsprechendem Interesse kann ich das aber gerne nachreichen.
Hier ein Video, dass ich kurzfristig auftreiben konnte… ist schon etwas älter. Mittlerweile verwende ich „Hey Computer“ als Keyword und die Hardware steckt in einem eigens konstruierten, 3D-gedrucktem Gehäuse. Aber es gibt schonmal einen kleinen Vorgeschmack. Bei Gelegenheit mache ich mal eine etwas ausführlicheres Video.